1. 概述与架构设计
本手册旨在指导开发人员在混合环境(本地开发 + 云端/集群计算)下,构建一套完整的历史地图数字化与分析平台。该平台服务于数字人文研究(如城市变迁分析)和数字文旅项目(如交互式历史地图导览)。
1.1 技术栈角色定义
表格
| 组件 | 角色定位 | 核心功能 | 部署环境建议 |
|---|---|---|---|
| IIIF Server | 数据入口与展示层 | 提供高分辨率图像的按需加载、缩放、裁剪 API;前端交互界面。 | 云端 (Web 服务器) / 本地 (开发测试) |
| MapReader | 智能核心 (AI Model) | 深度学习模型,负责识别地图中的地物(建筑、道路、水体等)。 | 本地 (GPU 训练/调试) / 云端 (推理服务) |
| MapKurator | 编排引擎 (Pipeline) | 分布式任务调度,批量调用 MapReader 处理海量 IIIF 图像,管理流程。 | 云端 (K8s/Spark 集群) / 本地 (Docker 模拟) |
| Parquet | 数据存储与分析层 | 高效列式存储格式,保存提取后的结构化地理数据,供快速查询。 | 对象存储 (S3/OSS) / 本地文件系统 |
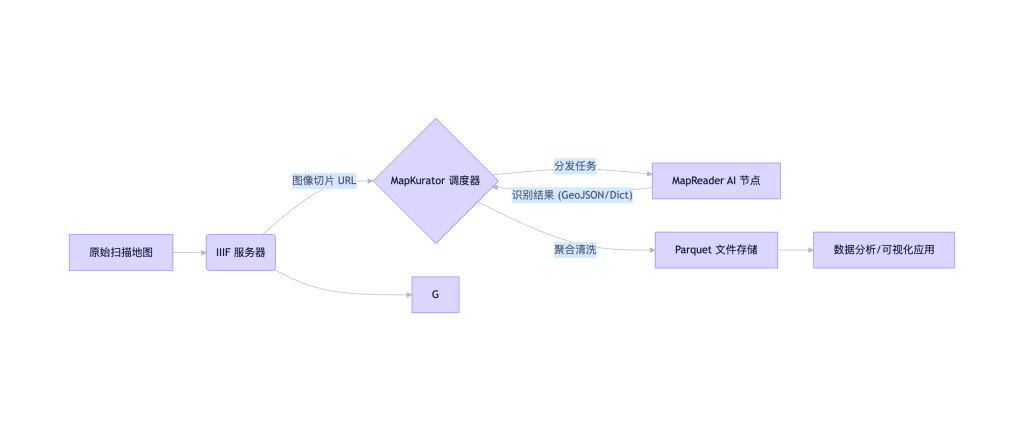
1.2 数据流向图
graph LR
A[原始扫描地图] --> B(IIIF 服务器)
B -- 图像切片 URL --> C{MapKurator 调度器}
C -- 分发任务 --> D[MapReader AI 节点]
D -- 识别结果 (GeoJSON/Dict) --> C
C -- 聚合清洗 --> E[Parquet 文件存储]
E --> F[数据分析/可视化应用]
B --> G[前端展示 (Mirador/自定义)]
F -.-> G
2. 环境准备与资源获取
2.1 硬件与软件依赖
- 计算节点:需配备 NVIDIA GPU (推荐 T4/A10/V100),用于运行 MapReader 模型。
- 存储:高性能对象存储(如 AWS S3, MinIO, 阿里云 OSS)用于存放 IIIF 图像和 Parquet 数据。
- 软件栈:
- Docker & Docker Compose (容器化部署)
- Python 3.9+ (PyTorch, Spark, Pandas)
- Java 11+ (若使用 Spark on YARN/K8s)
- Node.js (前端开发)
2.2 资源获取渠道
- 历史地图数据源:
- 公开库:British Library, David Rumsey Map Collection, 美国国会图书馆 (均支持 IIIF)。
- 自有数据:需先扫描并上传至 IIIF 服务器。
- 代码仓库:
- MapReader:
github.com/livecoast/mapreader(剑桥大学官方库) - MapKurator:
github.com/knowledge-computing/mapkurator(注意:需确认具体 fork 版本或内部发布版,此处以通用架构为例) - IIIF Server:
github.com/IIIF-Commons/iipimage或cantaloupe-project/cantaloupe(Java 实现,生产级推荐)。
- MapReader:
3. 部署指南 (混合环境策略)
3.1 第一阶段:IIIF 图像服务部署 (云端/公网)
目标:让地图可被网络访问,并支持动态切片。
- 工具选择:Cantaloupe (推荐,性能好,支持多种源)。
- 部署步骤:
- 准备图像:将高分辨率 TIFF/JPEG 地图上传至对象存储 (S3)。
- 配置 Cantaloupe:properties编辑
1# cantaloupe.properties 2source.client.username = <S3_ACCESS_KEY> 3source.client.secret_key = <S3_SECRET_KEY> 4source.client.endpoint_override = <S3_ENDPOINT> 5source.static.path_prefix = /maps/ - 启动服务:使用 Docker 运行。bash编辑
1docker run -d -p 8182:8182 -v ./config:/etc/cantaloupe ualbertalib/cantaloupe - 验证:访问
http://<IP>:8182/iiif/2/<image_id>/info.json查看是否返回 IIIF 清单。
3.2 第二阶段:MapReader 模型环境 (本地/云端 GPU)
目标:准备好能“看懂”地图的 AI 模型。
- 部署步骤:
- 克隆代码:bash编辑
1git clone https://github.com/livecoast/mapreader.git 2cd mapreader - 创建虚拟环境:bash编辑
1python -m venv venv 2source venv/bin/activate 3pip install -r requirements.txt - 下载预训练模型:
MapReader 通常提供针对英国 Ordnance Survey 地图的预训练权重。对于其他地图(如中国古地图),可能需要迁移学习。python编辑1# 示例代码:加载模型 2from mapreader import MapReader 3mr = MapReader() 4mr.load_model(model_path="pretrained_os_1890.pth") - 测试推理:在本地对单张小图进行测试,确保 GPU 可用。
- 克隆代码:bash编辑
3.3 第三阶段:MapKurator 流水线编排 (云端集群)
目标:大规模并行处理。
- 架构设计:MapKurator 通常基于 Spark 或 Celery 构建。
- 部署步骤:
- 配置任务队列:设置 Redis 作为消息 broker。
- 编写处理脚本 (
process_job.py):python编辑1def process_tile(iiif_url): 2 # 1. 从 IIIF 下载切片 3 img = download_image(iiif_url) 4 # 2. 调用 MapReader 推理 5 result = map_reader.predict(img) 6 # 3. 返回结构化数据 7 return result 8 9# MapKurator 主逻辑:遍历 IIIF Manifest 中的所有页面和切片 10# 提交任务到 Spark/Dask 集群 - 启动集群:在 Kubernetes 或 EMR 上提交 Spark Job,设置 Executor 数量为 GPU 节点数。
4. 数据操作流程 (核心业务)
4.1 数据加载 (Ingestion)
- 输入:IIIF Manifest URL (例如:
https://library.example.org/iiif/maps/china_1850/manifest.json)。 - 操作:
- MapKurator 解析 Manifest,获取所有画布 (Canvases) 和图像 ID。
- 根据地图分辨率,自动计算需要处理的切片网格 (Grid)。
- 生成任务列表:
[(image_id, x, y, zoom_level), ...]。
4.2 数据处理 (Processing)
- 执行:
- Worker 节点从 IIIF Server 拉取指定区域的图片块 (Patch)。
- MapReader 进行语义分割,输出像素级的分类掩码 (Mask)。
- 后处理:将 Mask 转换为矢量多边形 (Polygon),简化几何形状,添加属性(如
class: building,confidence: 0.95)。 - 坐标配准:如果原图有地理参考信息 (Georeferenced),将像素坐标转换为经纬度 (WGS84);若无,则保留相对坐标。
4.3 数据导出 (Export to Parquet)
这是关键步骤,将非结构化结果转为高效分析格式。
- Schema 设计:python编辑
1import pyarrow as pa 2 3schema = pa.schema([ 4 ('map_id', pa.string()), # 地图唯一标识 5 ('year', pa.int32()), # 地图年份 6 ('feature_type', pa.string()), # 地物类型:building, road, water 7 ('geometry_wkt', pa.string()), # WKT 格式的几何信息 8 ('confidence', pa.float32()), # 置信度 9 ('bbox_min_x', pa.float64()), # 边界框 10 ('bbox_min_y', pa.float64()), 11 ('bbox_max_x', pa.float64()), 12 ('bbox_max_y', pa.float64()) 13]) - 写入操作:python编辑
1import pandas as pd 2import pyarrow.parquet as pq 3 4# 假设 results 是处理后的 DataFrame 列表 5df_total = pd.concat(results) 6 7# 分区存储:按地图ID或年份分区,优化查询 8table = pa.Table.from_pandas(df_total, schema=schema) 9pq.write_to_dataset( 10 table, 11 root_path='s3://my-data-lake/historical-maps/processed/', 12 partition_cols=['year', 'feature_type'] 13)
4.4 数据利用 (Consumption)
导出的 Parquet 数据可直接被以下工具利用:
- 大数据分析 (Spark/Presto):
- 场景:统计 1900-1950 年某城市建筑密度的变化。
- SQL:
SELECT year, count(*) FROM maps WHERE feature_type='building' AND bbox_intersects(...) GROUP BY year
- GIS 集成 (QGIS/ArcGIS):
- 使用
geopandas读取 Parquet 并导出为 Shapefile/GeoJSON,叠加到现代地图上进行对比。 - python编辑
1import geopandas as gpd 2gdf = gpd.read_parquet("s3://.../year=1920/part-0.parquet") 3gdf.to_file("output_1920.geojson", driver="GeoJSON")
- 使用
- 数字文旅前端应用:
- 后端提供 API (FastAPI/Flask),接收前端请求,从 Parquet 中快速检索特定区域的 POI (兴趣点),返回 GeoJSON 给前端地图 (Mapbox/Leaflet) 渲染。
- 功能:游客点击地图上的“老火车站”,弹出历史介绍和 AI 识别的原始截图。
5. 应用场景实战案例
场景 A:数字人文研究 – “百年城市扩张分析”
- 数据:选取 1880, 1920, 1960, 2000 四期城市地图。
- 处理:MapKurator 批量处理,提取所有“建筑”和“道路”。
- 分析:
- 加载 Parquet 数据至 Jupyter Notebook。
- 计算各年份建成区面积。
- 生成热力图,展示城市扩张方向。
- 成果:发表学术论文,附带交互式时间轴地图。
场景 B:数字文旅项目 – “寻迹古城”小程序
- 数据:当地清末民初的老地图。
- 处理:识别古建筑、老字号店铺、城墙。
- 应用:
- 用户打开微信小程序,定位到当前位置。
- 系统查询 Parquet 数据库中该位置的历史数据。
- AR 叠加:在手机摄像头画面中,叠加显示 100 年前该位置的街道样貌(基于 IIIF 切片)和 AI 识别出的老店名称。
- 故事线:推送“您脚下曾是 XX 镖局所在地”的语音讲解。
6. 运维与优化建议
- 性能优化:
- IIIF 缓存:务必在 IIIF Server 前配置 Nginx 或 CDN 缓存切片,避免重复生成。
- Parquet 压缩:启用 Snappy 或 Zstd 压缩,减少存储成本和 I/O 延迟。
- 小文件合并:MapKurator 产生的大量小 Parquet 文件需定期合并 (Compaction),防止 NameNode 压力过大。
- 质量控制:
- 人工抽检:建立简单的标注界面,随机抽取 AI 识别结果进行人工校验,计算 IoU (交并比)。
- 反馈循环:将修正后的数据加入训练集,重新微调 MapReader 模型,提升特定区域地图的识别率。
- 安全与权限:
- 对于未公开的珍贵地图,IIIF Server 需配置 Token 认证。
- Parquet 数据存储在私有 Bucket,仅授权分析服务访问。
7. 常见问题排查 (FAQ)
- Q: MapReader 识别准确率低怎么办?
- A: 历史地图风格差异大。需收集少量目标地图样本,进行标注,使用 MapReader 的代码框架进行Fine-tuning (微调)。
- Q: Parquet 文件读取慢?
- A: 检查是否利用了谓词下推(在查询时过滤
year或type列),并确保文件按这些列进行了分区。
- A: 检查是否利用了谓词下推(在查询时过滤
- Q: IIIF 图片加载卡顿?
- A: 检查网络带宽,确认 IIIF Server 是否开启了瓦片缓存,或者原图分辨率过高导致动态切片计算超时(建议预处理生成金字塔 TIFF)。
本手册提供了从底层部署到上层应用的全链路方案。开发人员可根据实际项目规模,灵活调整集群大小和存储策略。