在现代前后端分离的 Web 系统中,数据质量已成为业务可靠性和用户体验的核心保障。传统的硬编码校验规则难以应对复杂、动态的业务语义,而全量离线审计又无法满足关键路径的实时性要求。为此,我们提出一种 “特征驱动的轻度内嵌 + 外部增强”双模式数据治理架构,通过将批量学习与实时推理有机结合,实现智能、可演进、低侵入的数据质量管控。
一、核心理念
让数据自己说话,用历史分布定义“正常”,用特征模型指导实时判断。
该架构包含两个协同工作的子系统:
- 轻度内嵌(Lightweight In-Process)
- 在数据插入/更新时执行基于特征模型的语义检查;
- 不阻塞主流程(可配置为警告或拦截);
- 检查逻辑完全由外部学习所得的特征驱动,非硬编码。
- 外部增强(External Enhancement)
- 定期对全量或增量数据执行深度特征学习与异常回溯;
- 支持统计分析、文本模式挖掘、分布偏移检测等高级能力;
- 学习结果以结构化形式持久化,供内嵌模块调用。
二者通过统一的特征仓库和异常记录表实现状态同步与闭环治理。
二、系统架构
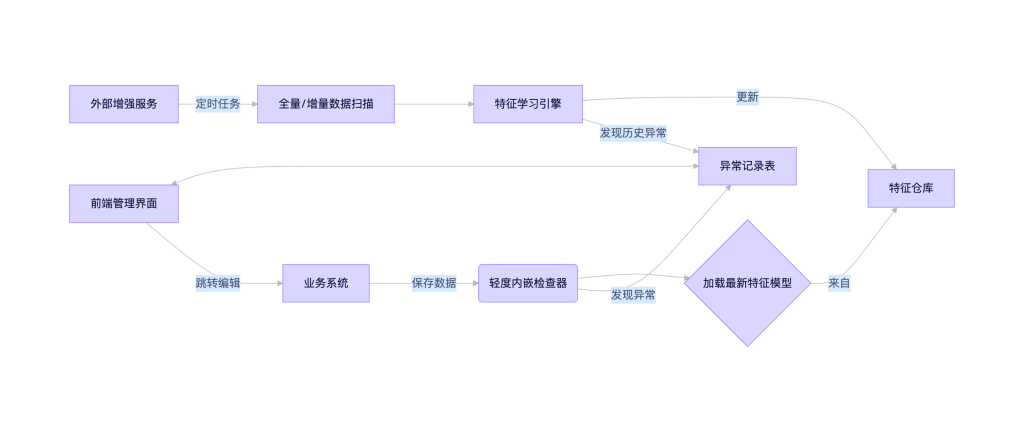
graph LR
A[业务系统] -->|保存数据| B(轻度内嵌检查器)
B --> C{加载最新特征模型}
C -->|来自| D[特征仓库]
B -->|发现异常| E[异常记录表]
F[外部增强服务] -->|定时任务| G[全量/增量数据扫描]
G --> H[特征学习引擎]
H -->|更新| D
H -->|发现历史异常| E
I[前端管理界面] <--> E
I -->|跳转编辑| A
三、关键组件设计
1. 特征仓库(Feature Repository)
存储每个模型字段的“正常数据特征画像”,支持版本管理。
表结构示例(field_feature_profiles):
| 字段 | 类型 | 说明 |
|---|---|---|
| model_name | VARCHAR | 数据模型名(如 User) |
| field_name | VARCHAR | 字段名(如 bio) |
| feature_type | VARCHAR | 特征类型(text_stats, numeric_dist, enum_set) |
| version | INT | 版本号,单调递增 |
| features | JSONB | 特征内容(如均值、标准差、高频词等) |
| trained_at | TIMESTAMP | 训练时间 |
| record_count | INT | 训练样本数 |
| is_active | BOOLEAN | 是否当前生效 |
✅ 支持 PostgreSQL JSONB 高效查询,或 Redis 缓存 active 版本加速访问。
2. 轻度内嵌检查器(In-Process Checker)
- 职责:在 ORM 的
save()或 API 的validate()阶段调用; - 输入:待保存的字段值;
- 处理:
- 查询特征仓库,获取该字段最新 active 特征;
- 基于特征进行语义合理性判断(如:长度是否偏离 2σ?是否缺失常见模式?);
- 若异常,生成可解释的提示信息,并创建
pending状态的异常记录;
- 策略:
- 关键字段 → 阻断保存;
- 描述性字段 → 允许保存,仅记录异常。
示例判断逻辑(文本字段):
if len(value) < (mean_len - 2 * std_len):
return f"文本长度({len(value)})显著低于正常水平(μ={mean_len:.1f})"
3. 外部增强服务(Enhancement Service)
- 触发方式:定时任务(每日凌晨)或事件驱动(如数据量增长 10%);
- 核心能力:
- 特征学习:从“已确认正常”的数据中提取统计/文本/结构特征;
- 异常回溯:使用更复杂的算法(如聚类、孤立森林、NLP 相似度)扫描历史数据;
- 模型更新:将新特征写入仓库,并激活新版本;
- 扩展任务:支持数据清洗、标准化、特征工程等衍生任务。
典型特征学习内容:
| 字段类型 | 学习特征 |
|---|---|
| 数值型 | min, max, mean, std, P5, P95 |
| 文本型 | 平均长度、标点比例、高频词集、句子完整性得分 |
| 枚举型 | 合法值集合、各值频次 |
| 日期型 | 合理时间范围、工作日/节假日分布 |
4. 异常记录与闭环治理
- 所有异常(无论来自内嵌或外部)统一写入
data_anomalies表; - 前端提供管理界面,支持:
- 按模型/字段/状态筛选;
- 查看异常详情与特征依据;
- 操作:确认有效、忽略、跳转编辑;
- 用户修复数据后,系统可自动清除相关异常(通过监听 save 事件)。
四、优势与价值
| 维度 | 优势 |
|---|---|
| 智能性 | 规则由数据驱动,自动适应业务变化 |
| 实时性 | 关键路径毫秒级语义校验 |
| 深度性 | 支持 NLP、统计、ML 等高级分析 |
| 可解释性 | 异常原因明确(如“低于均值 2σ”) |
| 可维护性 | 无需修改代码即可更新校验逻辑 |
| 扩展性 | 外部服务可复用为数据处理平台 |
五、适用场景
- 业务语义复杂、规则难以穷举的系统(如用户资料、商品描述、评论内容);
- 数据规模中等(万级至千万级),需兼顾性能与深度;
- 团队具备基础数据工程能力,但不希望引入重型数据治理平台;
- 追求“预防+发现+修复”闭环的数据质量体系。
六、演进建议
- MVP 阶段:实现数值/文本字段的基础特征学习 + 内嵌检查;
- 中期:增加 NLP 特征(如语言检测、情感倾向)、支持特征 A/B 测试;
- 长期:集成在线学习、异常自动修复、数据质量 SLA 报告。
结语
“特征驱动的轻度内嵌和外部增强双模式”不是简单的功能叠加,而是一种以数据为中心、持续学习演进的治理范式。它既避免了硬编码规则的僵化,又规避了纯离线审计的滞后,为现代 Web 系统提供了一条轻量、智能、可持续的数据质量保障路径。