目标:在保持“90 % 工程化 + 10 % AI”的核心原则下,为中小型出版社(或数字内容团队)搭建一套可落地、可扩展的智慧出版系统。
原则:
- 模块化 – 以“功能块”而非“层级”拆解。
- 可观测 – 每个块都配备监控与日志。
- 渐进迭代 – 先做 MVP,再逐步加深 AI 价值。
- 技术选型简洁 – 兼顾成熟度与成本,首选云原生与开源工具。
1. 先决条件
| 领域 | 具体需求 | 预估投入 |
|---|---|---|
| 业务 | 明确出版内容类型(学术、技术、通俗) | 无 |
| 数据 | ① 原稿文本 ② 现有排版模板 ③ 版权信息 ④ 读者行为日志 | 1–2 万字原稿、数百条读者日志 |
| 技术 | ① 具备基础的云账号(AWS/GCP/Azure) ② 具备 Docker/Kubernetes 经验 ③ 具备 Python 开发经验 | 1–2 人员 |
| 预算 | ① 云算力(按需计费) ② 3rd‑party API(如 OpenAI) | 月均 1 ~ 3 k 美元 |
说明:方案以 AWS + LangChain + Kubernetes + PostgreSQL 为技术栈,兼顾成本与成熟度;如果已有内部部署可替换为自建云或 OpenShift。
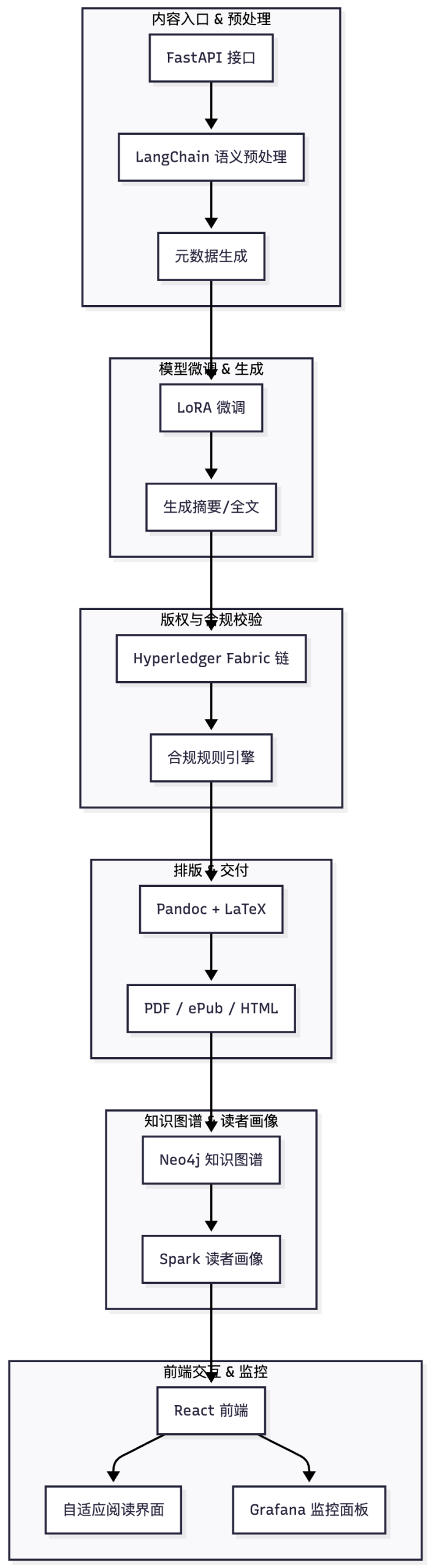
2. 方案结构(功能块视图)
| 序号 | 功能块 | 关键技术 | 主要任务 | KPI |
|---|---|---|---|---|
| 1 | 内容入口 & 语义预处理 | FastAPI + LangChain | ① 原稿上传 ② 分词、命名实体抽取 ③ 生成元数据 | 预处理时间 < 5 s |
| 2 | 模型微调 & 生成 | HuggingFace 🤗 Transformers + LoRA | ① 领域微调(技术/学术) ② 文本生成、摘要 | 生成准确率 ≥ 90 % |
| 3 | 版权与合规校验 | 区块链(如 Hyperledger Fabric) + 规则引擎 | ① 版权信息登记 ② 合规性自动扫描 | 合规率 100 % |
| 4 | 排版 & 交付 | Pandoc + LaTeX + PDFKit | ① 自动排版 ② 生成多格式(PDF、ePub、Web) | 交付时延 < 10 min |
| 5 | 知识图谱 & 读者画像 | Neo4j + Spark | ① 关联内容 ② 用户画像构建 | 画像覆盖率 ≥ 80 % |
| 6 | 前端交互 & 监控 | React + Grafana | ① 阅读端(自适应) ② 监控面板 | 阅读时长 ↑10 % |
备注:功能块 1–4 直接对应 1–4 层基础设施 + 5–7 层智能核心;功能块 5 对应业务中台;功能块 6 对应交互层。
3. 分阶段落地(时间线 6–8 周)
| 周次 | 阶段 | 关键里程碑 | 负责人 | 产出 |
|---|---|---|---|---|
| 1 | 需求调研 | 与编辑、版权、营销团队访谈 | 项目经理 | 需求文档、痛点清单 |
| 2 | 技术选型与原型 | 搭建 LangChain 原型 + 预处理 | 开发组 | 原稿上传 → 元数据生成 Demo |
| 3 | 模型微调 & 校验 | 选取 2–3 个领域模型 + LoRA 微调 | ML Engineer | 微调模型、验证集评估 |
| 4 | 排版 & 交付 | 自动排版脚本 + PDF 生成 | 开发组 | 交付多格式 Demo |
| 5 | 版权链 & 合规 | 区块链节点部署 + 规则引擎 | DevOps | 合规扫描 Demo |
| 6 | 前端交互 & 监控 | React 前端 + Grafana 面板 | 前端/DevOps | 交互式阅读 Demo + 监控 |
| 7 | 试点 & 反馈 | 选取 3 篇稿件全流程运行 | 运营 | 试点报告(时延、错误率、读者反馈) |
| 8 | 优化 & 上线 | 基于反馈迭代 | 全体 | 正式上线 MVP,持续监控 |
小提示:每周结束后做 1 h “Sprint Review”,确保快速迭代。
4. 关键技术实现细节
4.1 内容入口与预处理
- FastAPI:REST API,支持多文件上传。
- LangChain 的
LLMChain:先做命名实体抽取,再通过模板生成元数据(标题、摘要、关键词)。 - 存储:PostgreSQL + AWS S3(文件)。
4.2 模型微调
- HuggingFace Transformers + PEFT:使用 LoRA 仅微调 0.3 % 参数,显著降低算力。
- 训练数据:从公开期刊(arXiv、IEEE Xplore)采集 5k 论文,使用 Domain-Specific Prompt。
- 部署:推理服务使用 NVIDIA Triton + Docker。
4.3 版权链与合规
- Hyperledger Fabric:搭建私有链,记录内容哈希、作者信息、授权状态。
- 规则引擎:Drools 或 Python
pandas结合正则,扫描版权敏感词。
4.4 排版与交付
- Pandoc:支持 Markdown → PDF/HTML/ePub。
- LaTeX 模板:自定义排版风格,生成 PDF。
- Web 预览:使用
pdf.js或Calibre。
4.5 知识图谱
- Neo4j:节点(文章、作者、关键词)+ 边(引用、合作)。
- Spark:批量加载、相似度计算。
4.6 前端 & 监控
- React:自适应阅读视图,支持高亮、注释。
- Grafana:监控指标(上传时延、生成错误率、读者停留)。
5. 成本与资源估算
| 项目 | 估算 | 备注 |
|---|---|---|
| 云算力(按需) | $1,200 / 月 | 2 x m5.large + 1 x g4dn.xlarge |
| 模型 API(OpenAI) | $600 / 月 | 30 k tokens |
| 区块链节点 | $200 / 月 | 1 x m5.large |
| 开发与运维 | 2 FTE × 8 周 | 80 人日 |
| 合计 | ~$6,000–8,000 | 视团队规模与使用量而定 |
成本可通过自动化监控和批量推理进一步压缩。
6. 风险与缓解措施
| 风险 | 影响 | 缓解措施 |
|---|---|---|
| ① 模型性能低 | 内容质量受影响 | ① 采用 LoRA 微调,② 预训练数据质量提升 |
| ② 版权链不兼容 | 合规成本上升 | ① 采用标准化链码(如 ERC‑1155)+ 兼容层 |
| ③ 监控盲区 | 难以及时发现错误 | ① Grafana 警报 + 日志聚合 |
| ④ 资源耗尽 | 生产停滞 | ① 按需扩容 + 自动缩减 |
| ⑤ 用户接受度低 | 读者流失 | ① A/B 测试交互UI,② 快速迭代反馈 |
7. 关键绩效指标(KPI)
| KPI | 目标 | 监控周期 |
|---|---|---|
| 内容交付时延 | ≤ 10 min | 每日 |
| 生成内容准确率 | ≥ 90 % | 每周 |
| 合规错误率 | 0 % | 每月 |
| 读者平均停留 | ↑ 10 % | 每月 |
| 成本效率 | 运营成本下降 15 % | 每季度 |
8. 快速落地 Checklist
- 成立项目小组:项目经理、两名开发、一名 ML Engineer、DevOps。
- 准备环境:AWS 账户、K8s 集群、PostgreSQL、S3。
- 搭建 FastAPI + LangChain 原型(原稿 → 元数据)。
- 微调 1–2 个领域模型(LoRA + HuggingFace)。
- 编写排版脚本(Pandoc + LaTeX)。
- 部署 Hyperledger Fabric(本地或 AWS)。
- 前端小站(React + pdf.js)。
- 监控面板(Grafana + Prometheus)。
- 试点 3 篇稿件,记录 KPI。
- 迭代:根据反馈修正模型、规则、UI。
- 正式上线,开启持续监控与优化循环。
结语
- 核心思路:先建“低成本、可观测的流程骨架”,再逐步注入 AI 价值。
- 可扩展性:每个功能块都可独立替换或升级;模型可以按需换为更大或更精细的版本。
- 实施节奏:采用 2 周 Sprint,确保快速验证与调整。
通过上述轻量化方案,出版机构即可在几个月内搭建起可运营、可演进的智慧出版平台,为内容创作、审核、分发与阅读提供全链路的数字化支撑。